Личность в толпе: пределы конфиденциальности в мобильности человека
Недавно проводилось исследование в области мобильной конфиденциальности человека, привожу мой перевод данного анализа:
«Мы 15 месяцев исследовали данные, полученные от мобильных устройств, от одного до полумиллиона людей и обнаружили, что люди активно оставляют “мобильные следы”. Это факт, что данные о местоположении каждого человека можно определить точно, и с помощью пространственного анализа, основанного на антеннах сотовых операторов, четырёх пространственно-временных точек достаточно, чтобы идентифицировать 95% всех людей. Мы округлили пространственные и временные данные, чтобы найти формулу уникальности “мобильных следов”, что позволит нам получить недостающую информацию. Эта формула показывает, что уникальность мобильных следов уменьшается примерно на 1/10 силы анализа. Следовательно, даже грубые предположения предоставляют минимум анонимности. Эти исследования показывают фундаментальные ограничения на неприкосновенность частной жизни каждого взятого человека и имеют важное значение для разработки механизмов и институтов, посвящённых защите конфиденциальной информации.»
Введение
Современные информационные технологии, такие как интернет и мобильные телефоны, усиливают уникальность личности, что в дальнейшем приводит к увеличению проблем к конфиденциальной информации. Мобильные данные являются наиболее важной информацией, собираемой в данный момент. Мобильные данные содержат примерное местоположение человека и может быть использована для восстановления его передвижения через пространство и время. Индивидуальные мобильные следы T (Рисунки 1А-В) могут быть использованы для исследовательских целей и обеспечивают персонализированный сервис для пользователей. Список потенциально важной профессиональной и личной информации, которая может быть предоставлена человеку, может быть представлен, основываясь лишь на этом мобильном следе. Это включает в себя посещения человеком церкви, клиники или гостиницы.
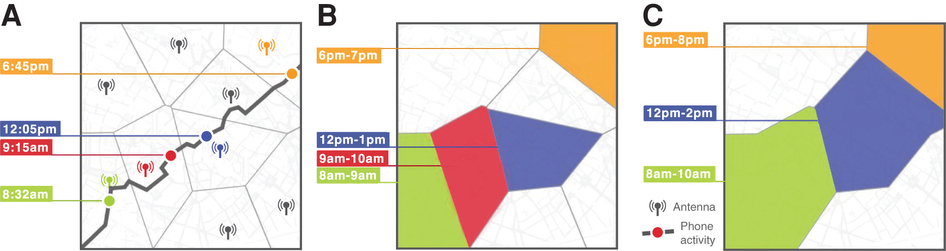
Рисунок 1. (А) След анонимного мобильного телефона в течении дня. Точки показывают время и местоположение, где пользователь делал или принимал вызов. Каждый раз как пользователь делает звонок, ближайшая антенна , которая перенаправляет вызов, записывает данные. (В) Такие же пользовательские следы записываются в мобильную базу данных. Решётки Вороного, показанные серыми линиями, показывают примерные зоны приёма антенн с наиболее точным местоположением по имеющимся у нас информации. Каждое пользовательское взаимодействие с сотовой сетью записывается с точностью в один час. (с) Такие же пользовательские следы, когда мы уменьшаем разрешение на наборе данных через пространственные и временные части. Антенны накапливают в кластеры размером в 2 кластера и объединяются вместе с ближайшими регионами. Пользовательские взаимодействия с сотовой сетью записываются с периодичностью в 2 часа. Каждые пространственные и временные части, передаваемые в 8.32 утра и в 9.15 утра не отличаются друг от друга. |
В прошлом, мобильные следы были доступны только сотовым операторам, но приход смартфонов и других методов сбора информации сделал эти данные хорошо доступными. Например, Apple недавно обновил политику конфиденциальной информации, позволяющей передавать гео-позицию их пользователей их партнёрам и лицензиатам. Огромное число приложений из App Store имеют доступ к гео-локации пользователя и практически 50% всего iOS и Android трафика доступно для рекламных сетей.
Простая анонимная информация не содержит в себе имени, домашнего адреса, телефонного номера или иного очевидного идентификатора. Тем не менее, если отдельные модели являются достаточно уникальными, то такая информация может связать с её владельцем. Например, в одном исследовании, медицинская база данных была успешно сопоставлена со списком избирателей, чтобы извлечь из медицинских записей губернатора Массачусетса (штат).
Результаты
Уникальность человеческой мобильности
В 1930 году, Эдмон Локард показал, что всего 12 точек соответствия достаточно для идентификации отпечатков пальцев. Наш уникальный тест оценивает количество точек p, необходимых для исключительной идентификации мобильного следа каждого взятого человека. Чем меньше необходимых точек, тем больше уникальных следов и тем легче они будут повторно переопределены, используя внешюю информацию. Для переидентификации, можно использовать любые внешние источники, такие как домашний адрес, место работы или гео-метку твита или картинки.
Учитывая Ip, набор пространственно-временных точек, и D, просто набор анонимных мобильных данных, мы оцениваем ε, уникальную следу, извлекая из D подмножество траекторий S (Ip), которые соответствуют с точки составлении Ip [см. Методы]. Путь уникален (единственный), если |S(Ip)| = 1, содержащий только один след. Например, на рис. 2A, мы оцениваем уникальность пути при Ip = 2. Эти две пространственно-временные точки, содержащиеся в Ip = 2 — зона I с 9 утра до 10 утра и зона II с 12 вечера до 1 часа ночи. Красные и зеленые следы, полученные при Ip = 2, делает их не уникальными. Тем не менее, мы также можем оценить уникальность следов, зная Ip = 3, добавляя в качестве третьей точки зону III между 15 и 16 часами. В этом случае |S(Ip = 3)| = 1, однозначно характеризуют зеленый след.
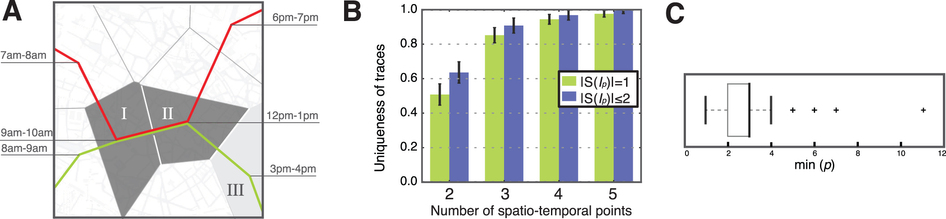
Рисунок 2. (A) Ip = 2 означает, что информация доступна атакующему между 7 и 8 утра пространственно-временными точками (I и II). Во всяком случае, цель была в зоне I между 9 и 10 утра и в зоне II между 12 и 1 часом ночи. В этом примере, следы двух анонимных пользователей (красный и зелёный) совмещаются с ограничениями, определяемых lp=2. Подмножество S(lp=2) состоит и более чем одного следа и поэтому не уникально. Тем не менее, зелёный след может быть уникально характеризован, если третья точка, в зоне III между 3мя и 4мя дня, будет добавлена (lp=3). (B) Уникальные следы в отношении к числу p пространственно-временных точек (lp). Зелёные полоски показывают долю уникальных следов, т.о. |S(Ip)| = 1. Синие полоски указывают на долю |S(Ip)| ≤ 2. Следовательно, зная несколько пространственно-временных точек, взятых случайным образом (Ip = 4), можно охарактеризовать примерно 95% следов из 1.5М пользователей. (С) График минимального числа пространственно-временных точек, необходимых для того, чтобы охарактеризовать каждый след на неагрегированной базе данных. В большинстве случаем достаточно 11 точек, чтобы однозначно охарактеризовать все следы. |
Наши данные содержат 15 месячные данные о 1.5М людей, значительная часть которых — маленькая европейская страна, примерно сопостовимо количеству пользователей гео-сервису Foursquare. Так же и для приложений или для электронных платежей, оператор мобильной связи записывает взаимодействия пользователя с его телефоном. Это создает сопоставимые дискретные данные [Рисунок 3]. В среднем, записывается 114 взаимодействий на пользователя в месяц с 6500 антенн. Антенны в нашей базе расположены по всей стране и обслуживают примерно ~2000 жителей каждая, покрывая территорию от 0.15 км2 в городах до 15 км2 в пригородных территориях. Количество антенн строго коррелирует с плотностью населения (R2 = 6426) [Рисунок 3С].

Рисунок 3. (A) Функция плотности вероятности количества записанных пространственно-временных точек на одного пользователя в течение месяца. (В) Функция средней плотности вероятности между временем взаимодействия с сервисом. (С) Количество антенн на регион, коррелирующий с текущим населением (R2 = 6426). Эти участки сильно подчеркивают дискретный характер нашего набора данных и его сходство с наборами данных, таких как собранных с приложения мобильного телефона. |
Масштабирующие свойства
Тем не менее, ε зависит от пространственного и временного разрешения набора данных. Здесь мы определим эту зависимость за счет снижения разрешения нашего набора данных через пространственные и временные агрегации [рис. 1С]. Мы делаем это путем увеличения размера области, объединеняя соседние клетки в кластеры клеток V, или уменьшая временное разрешение набора данных, увеличивая длину временного окна для наблюдения h часов [см. Методы]. Обе эти агрегации обязаны уменьшать ε и, следовательно, сделать ре-идентификации сложнее.
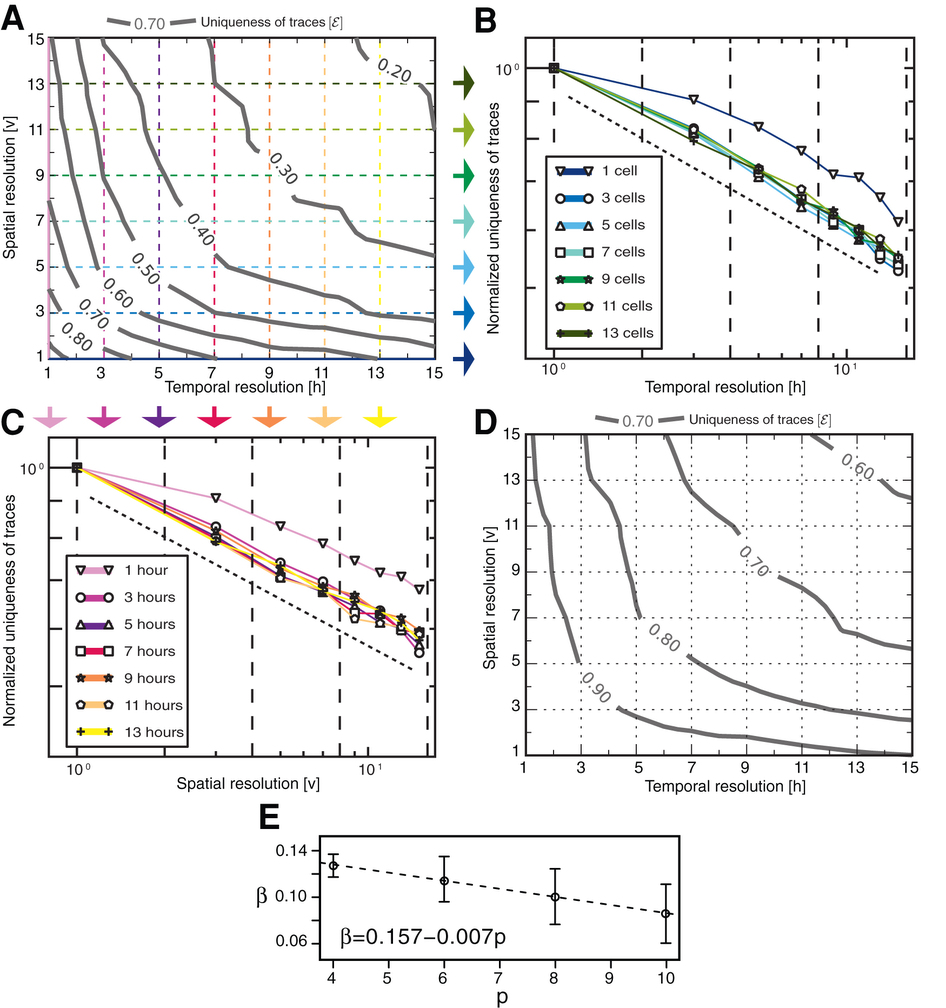
Рисунок 4. Уникальность следов [ε], когда мы уменьшаем разрешение данных с (А) р = 4 и (D) = 10 точек. Гораздо легче атаковать набор данных, который является грубым по одному измерению и точнымпо другому, чем среднезернистый набор данных по обоим измерениям. Даны четыре пространственно-временных точки, более чем 60% следов однозначно характеризуются в наборе данных с Н = 15-часовым временным разрешением, в то время как менее 40% следов однозначно характеризуется в наборе данных с временным разрешением H = 7 часов и с группами V = 7 антенн. Регионы, охваченные антеннами, колеблются от 0,15 км2 в городских районах до 15 км2 в сельской местности. (B-C) При уменьшении временного или пространственного разрешениея набора данных, уникальность следов уменьшается следуя степенной функцией ε = α — хβ. (E) Хотя ε уменьшается в зависимости от степенной функции, его показатель β линейно уменьшается с числом точек р. Соответственно, несколько дополнительных пунктов может быть достаточно для точной идентификации личности в наборе данных с более низким разрешением. |
По статистике, мы видим, что следы более уникальные, когда грубые по одному измерению и точные по другому, чем когда они среднезернистые по обоим измерениям. Действительно, имея четыре точки, ε> 0,6 в наборе данных с временным разрешением H = 15 часов или пространственным разрешением V = 15 антенн при ε > 0,4 в наборе данных с временным разрешением H = 7 часов. Пространственное разрешение V = 7 антенн [рис. 4A].
Далее мы покажем, что можно найти формулу для оценки уникальности данных следов, пространственного и временного разрешения данных, и число точек, доступных для внешнего наблюдателя. Рис. 4В и 4С показывают, что уникальность следа уменьшается по мере степенной функцией ε = α — хβ, для уменьшения пространственного и временного разрешения (х), и для всех рассматриваемых р = 4, 6, 8 и 10 (см. Таблицу S1 — http://www.nature.com/srep/2013/130325/srep01376/extref/srep01376-s1.pdf). Уникальность человеческой мобильности, таким образом, может быть выражена с помощью одной формулы: ε = α — (νh)β. Мы считаем, что эта функция мощности соответствует данным лучше, чем другие два параметра функции, такие как α — ехр (λх), растянутой экспоненциальной α — ехр хβ, или стандартной линейной функции α — βx (см. табл S1). Обе оценки для α и β весьма значимы (р < 0,001)32, и средняя псевдо-R2 составляет 0,98 для Ip = 4 делу и Ip = 10 случаев. Подходит хорошо на всех уровнях пространственной и временной агрегации [рис. S3A-B].
Степенная зависимость ε означает, что, в среднем, каждый раз, когда пространственное или временное разрешение следов делится на два, их уникальность уменьшается на постоянный коэффициент ~ (2)-β. Это означает, что приватность становится все труднее получить за счет снижения разрешения набора данных.
Рис. 2В показывает, что, как ожидается, ε увеличивается с р. Смягчающее действие р от ε непосредственно с показателем β, который распадается линейно с р: β = 0,157 — 0.007p [рис. 4E]. Зависимость β от р подразумевает, что несколько дополнительных пунктов может быть все, что необходимо для идентификации личности в наборе данных с более низким разрешением. В самом деле, имея четыре точки, снижая в два раза пространственное или временное разрешение, получим 9,3%, что менее вероятно, для идентификации личности, в то время имея десять точек, с тем же двух-кратным снижением результатов, сокращается лишь на 6,2% (см. таблицу S1).
Из-за функциональных зависимостей ε от р через показатель β, мобильные данные, вероятно, будут повторно реидентифицироваться, используя информацию только из внешних источников.
Эта же статья на Google Docs: http://goo.gl/kuuTY
Источник: http://www.nature.com/srep/2013/130325/srep01376/full/srep01376.html



Теперь что, даже любовницу завести станет невозможно?